Claude Code를 만든 엔지니어의 캐싱 설계: Claude API 요금을 절반 이하로
모델 등급을 낮추기 전에 같은 모델로 비용을 절반 이하로 줄이는 두 지렛대가 있습니다. 프롬프트 캐싱(읽기 90% 절감)과 Batch API(50% 할인)를 언제 어떻게 쓰는지 실제 숫자로 정리하고, Claude Code를 만든 엔지니어가 공개한 캐싱 설계 원칙까지 더했습니다.

“API 요금이 생각보다 빨리 불어난다.” LLM을 제품에 붙여본 팀이라면 한 번쯤 마주치는 순간입니다.
많은 경우 모델을 더 낮은 등급으로 내리기 전에 요금 구조 자체를 활용해 같은 모델로 비용을 절반 이하로 줄이는 지렛대가 두 개 있습니다. 바로 프롬프트 캐싱(Prompt Caching)과 Batch API입니다. 이 글은 둘이 각각 언제 효과적이고 코드로 어떻게 적용하는지 실제 숫자와 함께 정리합니다.
먼저 비용은 어디서 새는가
Claude API 비용은 결국 입력 토큰 × 단가 + 출력 토큰 × 단가입니다. 단가는 모델 등급(Haiku < Sonnet < Opus < Fable)에 따라 정해집니다. 컨텍스트 창이 1M이냐 200K이냐로 올라가지는 않습니다.
참고로, 2026년 6월 기준 주요 모델의 공식 요금은 다음과 같습니다(100만 토큰당, USD 기준).
모델 | 컨텍스트 창 | 입력 | 출력 |
|---|---|---|---|
Haiku 4.5 | 200K | $1 | $5 |
Sonnet 4.5 | 200K | $3 | $15 |
Sonnet 4.6 | 1M | $3 | $15 |
Opus 4.8 | 1M | $5 | $25 |
Fable 5 | 1M | $10 | $50 |
표를 보면 Sonnet 4.5(200K)와 Sonnet 4.6(1M)의 단가가 같다는 점이 눈에 띕니다.1 그럼 우리는 어떻게 비용을 줄일 수 있을까요? 즉 같은 모델을 쓰면서 비용을 줄이는 길은 두 가지입니다.
중복 입력을 다시 계산하지 않기 → 프롬프트 캐싱
실시간이 아니어도 되는 작업을 모아서 처리하기 → Batch API
지렛대 1: 프롬프트 캐싱 (반복되는 앞부분 재사용)
긴 시스템 프롬프트, 업로드한 문서, 코드베이스, 도구 정의처럼 요청마다 똑같이 들어가는 내용은 매번 새로 처리하면 낭비입니다. 프롬프트를 캐싱하면 이 고정 구간(prefix)을 캐시에 저장해두고 다음 요청에서 다시 계산하는 대신 꺼내 씁니다.
핵심은 가격 배수입니다. 기본 입력 단가를 1로 두면 배수는 다음과 같습니다.
동작 | 배수 | 의미 |
|---|---|---|
캐시 읽기(hit) | 0.1× | 재사용 시 90% 절감 |
5분 캐시 쓰기 | 1.25× | 처음 저장할 때만 |
1시간 캐시 쓰기 | 2× | 오래 유지할 때 |
최초 1회(캐시 쓰기)는 저장 비용(1.25×)을 더 내지만, 5분 안에 한 번만 재사용해도 그 즉시 비용을 회수합니다. 그 뒤로는 같은 prefix를 90% 낮은 비용으로 계속 읽습니다.2
적용법: cache_control을 고정 구간 끝에 붙인다
캐싱은 끄고 켜는 옵션이 아니라 “여기까지는 고정이다”라고 표시하는 브레이크포인트를 다는 방식입니다. 캐시할 블록 끝에 cache_control을 붙이면 됩니다. 핵심 원칙은 하나입니다. 고정 내용은 앞에, 매번 바뀌는 입력은 뒤에.
TypeScript
import Anthropic from "@anthropic-ai/sdk";
const anthropic = new Anthropic();
const res = await anthropic.messages.create({
model: "claude-opus-4-8",
max_tokens: 1024,
system: [
{ type: "text", text: "당신은 사내 코드베이스 도우미입니다." },
{
type: "text",
text: longCodebaseContext, // 수만 토큰짜리 고정 컨텍스트
cache_control: { type: "ephemeral" }, // 여기까지 캐시 (브레이크포인트)
},
],
messages: [
{ role: "user", content: userQuestion }, // 매번 바뀌는 부분은 캐시 뒤에
],
});
console.log(res.usage);
// cache_creation_input_tokens: 첫 요청에서 캐시에 '쓴' 토큰 (1.25x 과금)
// cache_read_input_tokens: 이후 요청에서 캐시로 '아낀' 토큰 (0.1x 과금)Python
import anthropic
client = anthropic.Anthropic()
res = client.messages.create(
model="claude-opus-4-8",
max_tokens=1024,
system=[
{"type": "text", "text": "당신은 사내 코드베이스 도우미입니다."},
{
"type": "text",
"text": long_codebase_context, # 수만 토큰짜리 고정 컨텍스트
"cache_control": {"type": "ephemeral"}, # 여기까지 캐시 (브레이크포인트)
},
],
messages=[{"role": "user", "content": user_question}],
)
print(res.usage)
# usage.cache_creation_input_tokens / usage.cache_read_input_tokens제대로 동작하는지는 응답의 usage로 바로 확인할 수 있습니다. 두 번째 요청부터 cache_read_input_tokens가 크게 잡히면 hit입니다. 계속 cache_creation만 잡힌다면 prefix가 매번 달라지고 있다는 신호입니다(타임스탬프·사용자 이름 등이 고정 구간에 섞여 있는지 점검).
알아둘 점
도구 정의도 캐시 대상입니다.
tools배열의 마지막 도구에cache_control을 붙이면 도구 묶음 전체가 캐시됩니다.기본 수명은 5분이며 재사용할 때마다 갱신됩니다. 더 드물게 캐싱한 정보를 쓴다면
cache_control: { type: "ephemeral", ttl: "1h" }로 1시간 옵션을 켭니다.최소 캐시 길이가 있습니다. Opus 4.8과 Sonnet 4.6/4.5는 1,024 토큰, Fable 5는 512 토큰, Haiku 4.5는 4,096 토큰이 최소 길이입니다. 이보다 짧으면 캐시되지 않습니다(에러 없이 그냥 무시).
prefix가 한 글자라도 다르면 hit가 아닙니다. 100% 동일해야 합니다.
적합한 상황: 챗봇·코딩 어시스턴트처럼 같은 시스템 프롬프트나 문서를 반복해서 태우는 실시간 서비스. 대화가 길어질수록 컨텍스트가 클수록 이득이 커집니다.
지렛대 2: Batch API (급하지 않은 작업을 절반 값에 처리)
응답이 즉시 필요 없는 작업이라면 Batch API가 답입니다. 여러 요청을 한꺼번에 제출해 비동기로 처리하는 대신 입력·출력 토큰이 모두 50% 할인됩니다.
대부분의 배치는 1시간 이내에 끝나고 결과는 모든 요청이 완료되거나 24시간 중 먼저 도달하는 시점에 받습니다(24시간 내 미완료 시 만료).
한 배치는 최대 10만 건 또는 256MB까지 처리합니다. 결과는 생성 후 29일간 내려받을 수 있습니다.3
요청별로 모델·파라미터를 다르게 넣을 수 있고 각 요청은 독립적으로 처리됩니다.
적용법: 제출 → 폴링 → custom_id로 결과 매칭
배치는 세 단계입니다. (1) 요청 목록을 제출하고 (2) 끝날 때까지 상태를 폴링한 뒤 (3) 결과를 받아 custom_id로 원래 작업과 짝지읍니다.
TypeScript
// 1) 제출: 요청마다 custom_id로 식별 (^[a-zA-Z0-9_-]{1,64}$)
const batch = await anthropic.messages.batches.create({
requests: docs.map((doc) => ({
custom_id: doc.id,
params: {
model: "claude-opus-4-8",
max_tokens: 1024,
messages: [
{ role: "user", content: "다음 문서를 3줄로 요약:\n" + doc.text },
],
},
})),
});
// 2) 폴링: 처리 끝날 때까지 (대부분 1시간 내)
let status = batch;
while (status.processing_status !== "ended") {
await new Promise((r) => setTimeout(r, 60_000)); // 1분 간격
status = await anthropic.messages.batches.retrieve(batch.id);
}
// 3) 결과 회수: custom_id로 원래 작업과 매칭
for await (const result of await anthropic.messages.batches.results(batch.id)) {
if (result.result.type === "succeeded") {
save(result.custom_id, result.result.message.content);
} else if (result.result.type === "errored") {
console.error(result.custom_id, result.result.error);
}
}Python
import time
# 1) 제출: 요청마다 custom_id로 식별 (^[a-zA-Z0-9_-]{1,64}$)
batch = client.messages.batches.create(
requests=[
{
"custom_id": doc["id"],
"params": {
"model": "claude-opus-4-8",
"max_tokens": 1024,
"messages": [
{"role": "user", "content": "다음 문서를 3줄로 요약:\n" + doc["text"]},
],
},
}
for doc in docs
],
)
# 2) 폴링: 처리 끝날 때까지 (대부분 1시간 내)
while client.messages.batches.retrieve(batch.id).processing_status != "ended":
time.sleep(60) # 1분 간격
# 3) 결과 회수: custom_id로 원래 작업과 매칭
for result in client.messages.batches.results(batch.id):
if result.result.type == "succeeded":
save(result.custom_id, result.result.message.content)
elif result.result.type == "errored":
print(result.custom_id, result.result.error)폴링이 부담되면 결과 단계만 별도 워커로 분리해도 됩니다. 핵심은 custom_id를 ‘내 DB의 레코드 키’와 일치시켜 두는 것입니다. 그래야 수만 건이 뒤섞여 돌아와도 정확히 제자리에 꽂힙니다.
적합한 상황: 대규모 평가(eval), 콘텐츠 모더레이션, 문서 일괄 요약·분류·태깅, 야간 배치 분석처럼 ‘지금 당장’이 아니어도 되는 대량 작업.
둘을 함께 쓰면
프롬프트 캐싱과 배치 API로 인한 할인은 겹쳐서 적용됩니다. 공유 컨텍스트(같은 지침·같은 기준 문서)를 가진 대량 요청을 배치로 처리하면 50% 할인 위에 캐시 읽기 90% 절감이 더해집니다. 적용 방법은 간단합니다. 각 배치 요청의 params.system에 동일한 고정 컨텍스트를 넣고 cache_control을 붙이되 배치는 5분을 넘기기 쉬우니 ttl: "1h"로 두는 예시 코드를 살펴봅시다.
TypeScript
requests: docs.map((doc) => ({
custom_id: doc.id,
params: {
model: "claude-opus-4-8",
max_tokens: 1024,
system: [
{
type: "text",
text: sharedRubric, // 모든 요청이 공유하는 고정 기준
cache_control: { type: "ephemeral", ttl: "1h" },
},
],
messages: [{ role: "user", content: doc.text }], // 요청별로 바뀌는 부분
},
})),Python
requests=[
{
"custom_id": doc["id"],
"params": {
"model": "claude-opus-4-8",
"max_tokens": 1024,
"system": [
{
"type": "text",
"text": shared_rubric, # 모든 요청이 공유하는 고정 기준
"cache_control": {"type": "ephemeral", "ttl": "1h"},
},
],
"messages": [{"role": "user", "content": doc["text"]}],
},
}
for doc in docs
](참고로 배치 안에서는 max_tokens: 0 캐시 프리워밍은 지원되지 않습니다. 첫 요청이 캐시를 채우고 뒤따르는 요청이 그 캐시를 읽습니다.)
뉴스레터
엔터프라이즈 현장 전문가들이 검증한 노트, 격주 발행.
Claude Code, GitHub Copilot, AI 네이티브 엔지니어링 전략과 도입 사례를 격주로 정리해 보내드립니다.
에이전트를 직접 만든다면: 캐시가 깨지지 않게 설계하기
여기까지는 호출 하나의 비용을 낮추는 방법이었습니다. 그런데 챗봇이나 코딩 어시스턴트처럼 한 세션이 수십 턴씩 이어지는 서비스라면 결이 조금 다릅니다. 캐시는 매 턴 같은 앞부분(prefix)을 재사용할 때만 비용 우위가 생기는데, 세션이 길어질수록 그 prefix를 깨뜨릴 틈도 많아집니다. 한 번 깨지면 그 뒤 컨텍스트 전체를 제값 주고 다시 처리합니다. 마침 이 문제를 제품 규모로 부딪힌 팀이 있습니다. Claude Code를 만든 엔지니어들이 자신들의 하네스를 캐싱 위에 통째로 설계하며 얻은 교훈을 공개했는데8, 핵심만 추리면 이렇습니다.
출발점은 하나입니다. 캐시는 prefix 매칭입니다. 요청은 항상 도구 정의 → 시스템 프롬프트 → 대화 메시지 순서로 쌓이고, 앞에서 한 바이트라도 달라지면 그 뒤가 전부 무효가 됩니다. 그래서 Claude Code는 내용을 잘 안 바뀌는 것부터 자주 바뀌는 것 순으로 층을 나눠 둡니다. 정적 시스템 프롬프트와 도구 정의(전역에서 공유) → 프로젝트 컨텍스트(CLAUDE.md) → 세션 컨텍스트 → 대화 메시지. 이렇게 쌓으면 서로 다른 세션끼리도 앞 층을 최대한 같이 캐시합니다. 원칙은 앞에서 본 것과 같습니다. 고정은 앞에, 변하는 건 뒤에. 다만 세션이 길어지면 이 단순한 원칙을 지키기가 의외로 까다롭습니다.

갱신은 프롬프트가 아니라 메시지로
세션 도중 정보가 바뀌는 일은 흔합니다. 날짜가 넘어가고 사용자가 파일을 고치고 모드가 바뀝니다. 요청은 늘 앞쪽에 고정된 시스템 프롬프트(캐시되는 prefix)와 그 뒤에 매 턴 쌓이는 대화 메시지로 나뉜다는 점을 떠올려 봅시다. 이때 앞쪽 시스템 프롬프트를 고쳐 넣고 싶은 유혹이 들지만, 그러면 prefix가 바뀌어 그 뒤 캐시가 통째로 무효가 됩니다. Claude Code의 방법은 반대입니다. 바뀐 정보를 앞쪽 시스템 프롬프트가 아니라 대화 맨 뒤에 새로 붙는 메시지에 담아 보냅니다. 예를 들어 오늘이 수요일이라는 갱신은 다음 사용자 메시지나 도구 결과에 <system-reminder> 태그로 끼워 넣습니다. 새 메시지는 캐시된 prefix 뒤에 붙으므로 앞 층은 그대로 살아 있습니다.
const res = await anthropic.messages.create({
model: "claude-opus-4-8",
max_tokens: 1024,
system: [
{ type: "text", text: STABLE_SYSTEM, cache_control: { type: "ephemeral" } },
],
messages: [
...history, // 캐시된 대화 (prefix 유지)
{ role: "user", content: userMessage },
// 바뀐 맥락은 시스템 프롬프트가 아니라 여기에
{ role: "system", content: "지금은 수요일입니다." },
],
});대화 중간에 시스템 메시지를 끼우는 이 방식은 베타(mid-conversation-system-2026-04-07)로 Opus 4.8 같은 모델에서 쓸 수 있고, 미지원 모델에서는 같은 효과를 사용자 메시지 안의 <system-reminder> 텍스트로 냅니다.
상태 전환은 도구로 모델링한다
필요에 따라 도구를 켜고 끄고 싶을 때도 같은 함정이 있습니다. 도구 정의는 prefix의 맨 앞(위치 0)이라, 세션 도중 도구를 하나 추가하거나 빼면 그 세션의 캐시 전체가 무효가 됩니다. 그래서 Claude Code는 도구 묶음을 절대 바꾸지 않습니다. 대신 상태 전환 자체를 도구로 만듭니다. 플랜 모드가 좋은 예입니다. 읽기 전용 모드로 들어갈 때 도구 목록을 읽기 전용으로 갈아끼우는 대신, EnterPlanMode와 ExitPlanMode를 도구로 두고 모델이 그걸 호출해 모드를 바꿉니다. 도구 정의는 한 번도 안 바뀌니 캐시가 유지되고, 부수적으로 모델이 어려운 문제를 만나면 스스로 플랜 모드에 들어갈 수도 있습니다.
도구가 수십 개라 매 요청에 다 싣기 부담스러운 경우(MCP 도구가 많은 상황)도 빼는 대신 미룹니다. 이름만 담은 가벼운 stub을 항상 같은 순서로 두고(defer_loading), 모델이 도구 검색으로 필요할 때만 전체 스키마를 불러옵니다. prefix는 늘 같은 stub 묶음이라 안정적입니다. 이 도구 검색은 Claude API에서도 그대로 제공됩니다.
세션 중에는 모델도 바꾸지 않는다
캐시는 모델마다 따로 쌓입니다. 그래서 직관과 어긋나는 상황이 생깁니다. Opus로 10만 토큰을 쌓아 둔 대화에서 쉬운 질문 하나를 더 저렴한 Haiku로 넘기면, Haiku용 캐시를 처음부터 다시 쌓아야 해서 그냥 Opus로 답하는 것보다 비쌉니다. 모델을 굳이 바꿔야 한다면 같은 대화 안에서 갈아타지 말고 서브에이전트로 분리하는 편이 낫습니다. 메인 대화는 한 모델로 유지하고, 더 저렴한 모델이 맡을 일은 작업 요약을 핸드오프로 넘겨 따로 처리합니다. Claude Code의 탐색용 Explore 에이전트가 이렇게 Haiku를 씁니다.
캐시를 깨뜨리는 실수는 대개 사소한 데서 나옵니다. 정적 프롬프트에 심어 둔 타임스탬프, 매번 순서가 바뀌는 도구 정의, 도구 파라미터를 슬쩍 바꾸는 일, 세션 도중 도구 추가·삭제. 지금 필요한 도구만 주자는 생각은 합리적으로 들리지만 바로 그게 캐시를 깨는 대표적인 경로입니다.
곁가지 작업도 같은 prefix로
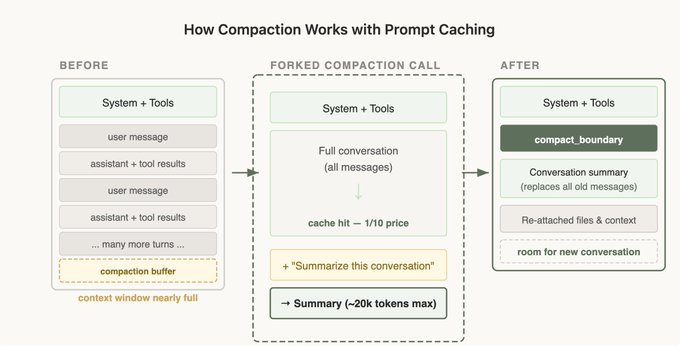
대화가 컨텍스트 창을 넘어설 것 같으면 지금까지를 요약해 새로 잇는 컴팩션이 필요합니다. 이걸 순진하게 구현하면 여기서도 캐시가 무효가 됩니다. 요약하려고 시스템 프롬프트도 도구도 없는 별도 호출을 날리면, 본 대화의 prefix와 한 글자도 일치하지 않아 그 큰 입력을 전부 제값에 다시 처리합니다. Claude Code는 부모 대화와 똑같은 시스템 프롬프트·컨텍스트·도구 정의를 그대로 쓰고, 그 뒤에 요약 지시만 새 메시지로 붙입니다. API 눈에는 부모의 마지막 요청과 거의 같은 요청이라 prefix가 그대로 재사용됩니다. 요약·서브에이전트·스킬 실행처럼 곁가지로 새 호출을 띄울 때의 원칙도 같습니다. 부모의 prefix를 그대로 물려받고 다른 점은 맨 끝에만 둔다. 참고로 컴팩션은 까다로워서 Claude API에 기능으로 내장돼 있으니, 직접 만들 게 아니라면 그 기능을 켜면 됩니다.
마지막으로 Claude Code 팀은 캐시 히트율을 서비스 가용성처럼 감시합니다. 히트율이 떨어지면 알림을 띄우고 장애로 다룹니다. 미스율 몇 퍼센트가 비용과 응답 속도를 크게 흔들기 때문입니다. 정리하면 에이전트를 직접 만든다면 캐시는 켜고 끄는 옵션이 아니라 시스템을 떠받치는 전제입니다. prefix가 깨지지 않도록 설계 전체를 거기에 맞추면 나머지 캐싱은 대부분 저절로 따라옵니다.
코드를 꼭 써야 하는 건 아니다
여기까지는 Claude API로 직접 제품을 만드는 경우의 이야기입니다. 그렇다면 Claude Code 같은 도구를 ‘사용’하기만 하는 사람은 어떨까요? 결론은 만드는 사람은 코드로, 쓰는 사람은 자동 + 명령으로입니다.
프롬프트 캐싱은 Claude Code에서 자동으로 적용됩니다. 시스템 프롬프트,
CLAUDE.md, 읽어들인 파일 같은 정적 컨텍스트를 도구가 알아서 캐시로 마킹해 다음 턴에 같은 prefix를 0.1배로 재사용합니다. 여러분은cache_control을 직접 쓸 일이 없고 터미널에서/cost로 캐시 히트율과 비용을 보며 무엇을 장기 기억시킬지 고민하면 됩니다.4Batch API는 대화형 CLI에는 해당하지 않습니다. 클로드 코드는 즉시 응답하는 도구라 비동기 배치 개념 자체가 없습니다. 배치는 ‘수만 건을 모아 한꺼번에 돌리는’ 백엔드 작업용입니다.
대신 사용자가 프롬프트·명령으로 직접 제어하는 절약 레버는 따로 있습니다. 컨텍스트 관리(
/clear,/compact, rewind), 모델 선택(/model), 불필요하게 큰 출력(긴 로그·grep 결과) 줄이기가 대표적입니다.
자동 캐싱이라도 ‘잘 먹게’ 돕는 습관은 있습니다. 세션 도중 CLAUDE.md나 초반 지시를 자꾸 바꾸지 마세요. 앞부분이 바뀌면 그 뒤 캐시가 통째로 무효화됩니다. 하나의 작업은 가급적 한 세션에서 이어가는 편이 캐시 히트율에 유리합니다.
숫자로 보는 효과
고정 컨텍스트 5만 토큰(시스템 + 기준 문서)을 매 요청에 태우는 작업을 Opus 4.8(입력 $5/MTok) 기준으로 진행중이라 가정해 봅니다.
최적화 없음: 요청당 입력 50,000 × $5/MTok = $0.25
캐싱 적용(반복 요청, hit): 요청당 50,000 × $0.50/MTok = $0.025 → 약 90% 절감
배치 + 캐싱(대량 비실시간): 여기에 출력까지 50% 할인이 더해져 총비용이 한 번 더 내려감
실시간 트래픽 1,000건/일이라면 입력 비용만 $250 → $25 수준으로 떨어지는 셈입니다. 모델을 낮추지 않고도 말이죠.
팀·엔터프라이즈 단위로 더 줄이기
여기까지가 호출 하나의 비용을 낮추는 이야기였다면, 팀으로 가면 결이 조금 달라집니다. 개발자 여럿이 같은 API 키로 정량 과금을 쓰기 시작하는 순간, 비용은 ‘호출당 몇 센트’ 문제가 아니라 ‘이 돈이 대체 어디서 나가는가’ 문제가 됩니다. 엔터프라이즈 계정을 실제로 굴려본 사람들이 입을 모으는 절약 방법을 모아봤습니다.
비용을 먼저 보이게 만든다
가장 먼저 부딪히는 벽은 의외로 기술이 아니라 가시성입니다. 청구서는 이번 달 총액 하나만 덩그러니 보여줄 뿐, 어느 팀이 어느 프로젝트에서 얼마를 썼는지는 말해주지 않습니다.6 그래서 Usage and Cost API5로 토큰 소비를 실시간으로 끌어와 대시보드를 직접 만들거나, 워크스페이스를 팀·프로젝트별로 갈라 spend limit으로 상한을 걸어둡니다. 더 잘게 쪼개 보고 싶으면 호출 앞단에 게이트웨이를 두고 요청마다 꼬리표를 답니다. 새는 곳이 안 보이면 무슨 최적화를 해도 결국 감으로 하는 셈입니다.
워크스페이스가 곧 캐시 경계다
의외로 놓치기 쉬운 함정이 하나 있습니다. 2026년 2월부터 프롬프트 캐시는 워크스페이스 단위로 격리됩니다. 같은 시스템 프롬프트를 공유하는 팀이 각자 다른 워크스페이스에 흩어져 있으면, 분명 같은 내용을 보내는데도 캐시를 나눠 쓰지 못하고 저마다 처음부터 다시 씁니다. 공유 컨텍스트로 도는 서비스라면 한 워크스페이스로 모아두는 것만으로 캐시 히트율이 올라갑니다.
모델 라우팅을 팀 기본값으로
모든 요청을 Opus로 보내는 팀이 생각보다 많습니다. 제일 똑똑한 모델이 제일 안전해 보이니까요. 그런데 분류하고 라우팅하고 짧게 추출하는 일까지 Opus를 쓰는 건 택시로 편의점 가는 격입니다. 가벼운 일은 Haiku, 대부분의 프로덕션 작업은 Sonnet, 정말 머리를 써야 하는 추론만 Opus로 올리는 캐스케이드를 팀의 기본값으로 정착시키세요. extended thinking도 마찬가지로 필요한 작업에만 켜고 thinking 토큰 예산을 난이도에 맞춰 잘라둡니다.
비실시간 작업은 배치로 모은다
평가(eval), 백필, 야간 리포트처럼 ‘지금 당장’이 아니어도 되는 일이 팀 곳곳에서 실시간 호출로 조용히 돌고 있는 경우가 많습니다. 이런 작업을 배치 파이프라인 하나로 모으면 같은 일을 절반 값에 처리합니다. 흩어진 비실시간 작업을 찾아 배치로 옮기는 것만으로도 청구서에 찍힌 비용이 눈에 띄게 줄어듭니다.
컨텍스트 위생과 계약
마지막은 덜 화려하지만 꾸준히 돈을 아끼는 습관입니다. 시스템 프롬프트의 군살을 덜어내고 대화 히스토리도 무한정 쌓는 대신 주기적으로 정리합니다. 에이전트라면 context editing으로 오래된 도구 결과를 비우는 것만으로 입력 토큰이 직접 줄어듭니다. 한 팀은 캐싱·배치·컨텍스트 정리를 함께 적용해 세션당 토큰을 약 60% 줄였다고 합니다.7 그리고 규모가 정말 커졌다면 표준 단가만 들여다보지 말고 엔터프라이즈 영업에 대량·약정 할인을 한번 물어보세요. 생각보다 협상 여지가 있습니다.
정리: 의사결정 한 줄
같은 프롬프트를 반복하는 실시간 서비스 → 프롬프트 캐싱을 먼저 켜고
usage로 hit를 확인한다.응답이 즉시 필요 없는 대량 작업 → Batch API로 돌리고
custom_id로 매칭한다.공유 컨텍스트의 대량 비실시간 작업 → 둘을 겹치고, 캐시는
ttl: "1h"로 둔다.Claude Code를 쓰기만 한다면 → 캐싱은 자동이니,
/clear·/compact·/model로 컨텍스트를 관리하는 데 집중한다.
요금 청구서를 보고 모델 등급부터 낮추기 전에 이 지렛대로 같은 품질을 유지한 채 비용을 절반 이하로 줄일 수 있는지 먼저 점검해 보세요. 대부분의 LLM 활용에서 가장 빠른 비용 개선은 모델 교체가 아니라 요금 구조를 제대로 쓰는 것에서 나옵니다.
참고 자료
Claude API Pricing, Context windows (모델별 단가·컨텍스트 창·장문 표준 요금)
↩Prompt caching (캐시 배수·최소 토큰·워크스페이스 격리)
↩Message Batches API (50% 할인·처리 시간·한도)
↩How Claude Code uses prompt caching (Claude Code 자동 캐싱)
↩Usage and Cost API (사용량·비용 모니터링)
↩Manage costs in Claude Code (워크스페이스 spend limit 등)
↩Claude API Cost Optimization (dev.to) (세션당 약 60% 절감 실사용 보고)
↩Lessons from Building Claude Code: Prompt Caching Is Everything (Claude Code 엔지니어가 공개한 캐싱 설계 원칙)
↩
이 글은 모던웹연구소 (www.modernweblabs.com)에서 처음 발행되었습니다. © 모던웹연구소. 무단 전재 및 재배포를 금합니다.
뉴스레터
엔터프라이즈 현장 전문가들이 검증한 노트, 격주 발행.
Claude Code, GitHub Copilot, AI 네이티브 엔지니어링 전략과 도입 사례를 격주로 정리해 보내드립니다.
모던웹연구소 · 컨설팅 안내
글을 읽었다면, 다음은 팀에 이식할 차례입니다.
이 글에서 다룬 방식을 우리 팀에 어떻게 적용할지, 짧은 대화부터 시작하면 됩니다.
함께할 수 있는 일
Claude Code · GitHub Copilot
2일 핸즈온 + AI 채점 기반 사내 인증
AI 네이티브 전략
운영 표준·측정·거버넌스 재설계
웹 플랫폼
Next.js 기반 풀스택 서비스 구축