코드베이스를 인수인계받았을 때 '분석해 줘' 대신 쓰는 acquire-codebase-knowledge 스킬
낯선 코드베이스를 인수인계받았을 때 '이 프로젝트 분석해 줘'라는 요청은 결과가 매번 다릅니다. awesome-copilot의 acquire-codebase-knowledge 스킬은 증거 기반 원칙과 7개 문서 체계로 AS-IS 분석을 재현 가능한 작업으로 바꿉니다. 스킬의 구조와 scan.py의 설계 원리까지 정리합니다.
운영 중인 서비스를 통째로 넘겨받는 순간이 있습니다. 전임 개발사가 계약을 끝냈거나 담당자가 퇴사했거나 이유는 다양하지만 상황은 같습니다. 문서는 낡았고 코드는 방대하고 질문할 사람은 없습니다. 모던웹연구소는 최근 플러터 앱을 인수인계받아 개발할 일이 생기면서 같은 상황을 겪었습니다. 이때 큰 도움을 받은 도구가 awesome-copilot의 acquire-codebase-knowledge 스킬입니다. 써보니 AS-IS 분석의 품질이 눈에 띄게 달라져서 스킬의 구조와 설계 원리를 정리해 공유합니다.
'이 프로젝트 분석해 줘'가 실패하는 이유
코딩 에이전트에게 "이 프로젝트 분석해 줘"라고 요청하면 뭔가 나오기는 합니다. 문제는 결과가 매번 다르다는 점입니다. 어떤 날은 아키텍처를 길게 설명하고 어떤 날은 의존성 목록만 나열합니다. 무엇을 어디까지 조사할지 기준이 없으니 에이전트가 그때그때 판단하기 때문입니다.
더 위험한 문제는 추측입니다. 에이전트는 dbUrl이라는 변수명만 보고 데이터베이스 종류를 단정하거나 디렉터리 몇 개를 훑고 '클린 아키텍처를 따른다'고 서술하곤 합니다. 인수인계 상황에서는 이런 추측을 검증해 줄 사람이 없습니다. 잘못된 분석 문서는 없는 것보다 나쁩니다. 팀 전체가 틀린 지도를 들고 개발을 시작하게 되기 때문입니다.
모던웹연구소 역시 기존에는 "인증 관련 코드 분석하고 설계 문서 남겨줘"처럼 영역별로 즉흥 요청을 던지는 방식으로 분석했습니다. 결과물의 형식도 깊이도 요청마다 달랐고 빠뜨린 영역이 있는지 확인할 방법도 없었습니다.
awesome-copilot과 acquire-codebase-knowledge
awesome-copilot은 GitHub 조직 계정에서 관리하고 커뮤니티가 함께 만들어가는 컬렉션입니다.1 커스텀 에이전트·지침·스킬·훅·플러그인·에이전틱 워크플로가 종합 선물 세트처럼 담겨 있어 자기만의 에이전트 환경을 꾸릴 때 영감받기 좋습니다. 오랜만에 들어가면 좋은 자료가 잔뜩 추가되어 있는 곳이기도 합니다.
그중 acquire-codebase-knowledge는 기존 코드베이스 전체를 파악해 문서화하는 스킬입니다.2 "map this codebase"나 "onboard me to this repo" 같은 저장소 수준의 탐색 요청에만 트리거되고 일반적인 기능 구현이나 버그 수정에는 개입하지 않습니다. MIT 라이선스이고 Python 3.8 이상과 git만 있으면 동작합니다.
결과물은 docs/codebase/의 7개 문서
스킬이 끝나면 docs/codebase/ 폴더에 정확히 7개의 문서가 남습니다.
STACK.md언어·런타임·프레임워크와 전체 의존성STRUCTURE.md디렉터리 구조·진입점·주요 파일ARCHITECTURE.md레이어·패턴·데이터 흐름CONVENTIONS.md네이밍·포맷팅·에러 처리·import 규칙INTEGRATIONS.md외부 API·데이터베이스·인증·모니터링TESTING.md테스트 프레임워크·파일 구성·mocking 전략CONCERNS.md기술 부채·보안 리스크·성능 병목·알려진 문제
인수인계란 전임자가 정리하지 않고 떠난 사무실 서랍을 여는 일과 비슷합니다. 무엇이 어디 있는지 아는 사람이 없으니 서랍마다 라벨부터 붙여야 합니다. 7개 문서가 그 라벨 역할을 합니다.
컨설팅 관점에서 특히 주목할 문서는 CONCERNS.md입니다. 이 문서는 빈 문서가 아니라 채워야 할 표가 미리 정해진 템플릿입니다. 심각도 순으로 정리한 리스크 표, 기술 부채 표, OWASP 분류를 함께 적는 보안 우려 표, 성능·확장성 문제 표, 최근 수정이 잦았던 취약 영역 표를 하나씩 채우게 되어 있습니다. 이 표들만 채워도 AS-IS 진단 보고서의 뼈대가 나옵니다.
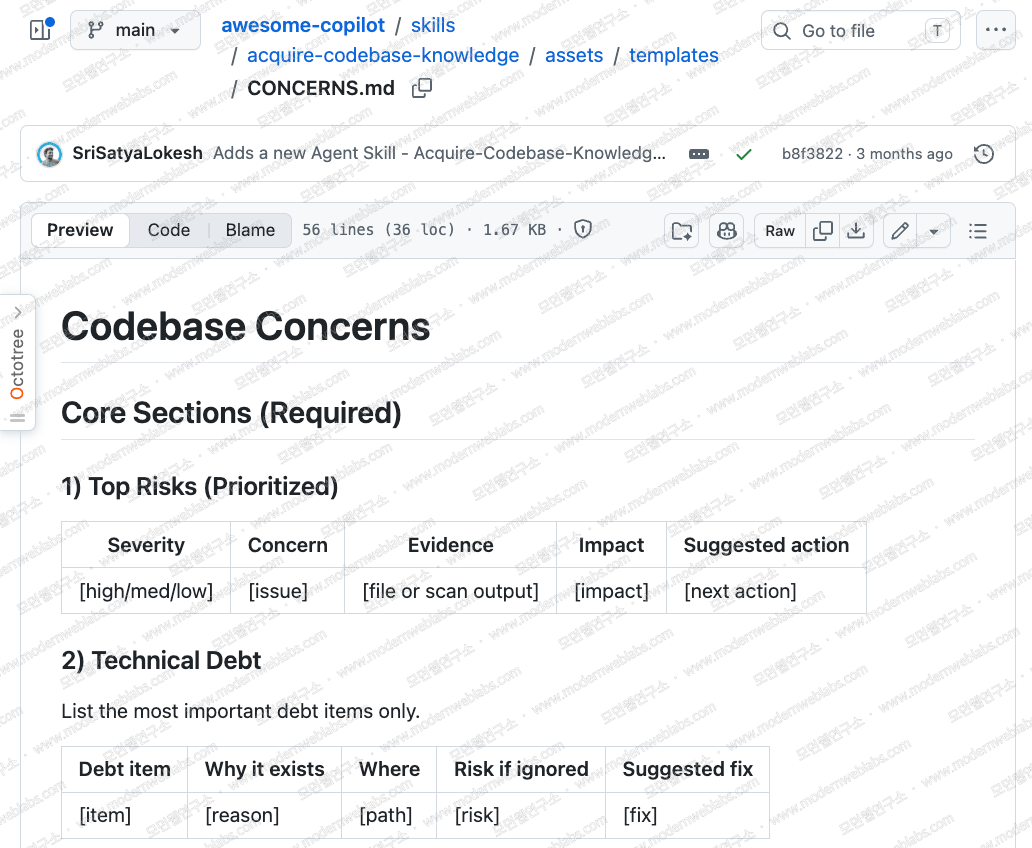
추측을 막는 장치
이 스킬의 핵심 원칙은 증거 기반 문서화입니다. SKILL.md에는 작업을 끝낸 것으로 인정받기 위한 완료 조건이 계약(Output Contract)이라는 이름으로 명시되어 있습니다. 에이전트가 7개 문서에 남기는 모든 내용은 실제 파일·설정·터미널 출력으로 근거를 댈 수 있어야 하고, 각 문서에는 근거가 된 파일 경로 목록을 함께 남기도록 설계되어 있습니다. 근거를 찾지 못한 내용은 [TODO]로 남기고, 코드만으로는 답할 수 없어 팀의 의도를 물어야 하는 결정은 [ASK USER]로 표시도 해줍니다. 에이전트가 그럴듯한 답을 지어내는 대신 '모르는 것은 모른다'고 말하게 강제하는 장치입니다.
안티패턴 목록도 구체적입니다. 해당 디렉터리가 없는데 "Domain/Data 레이어의 클린 아키텍처를 쓴다"고 쓰지 마라, package.json을 확인하기 전에 "Next.js 프로젝트다"라고 쓰지 마라, 변수명으로 데이터베이스를 추측하지 말고 매니페스트에서 pg·mysql2·prisma 같은 실제 의존성을 확인하라는 식입니다.
실무에서 자주 틀리는 지점을 짚은 주의사항도 스킬 안에 들어 있습니다. 몇 가지만 옮기면 이렇습니다.
README는 '의도'의 기록일 수 있다. 실제 파일 구조와 교차 검증하기 전에는 사실로 취급하지 않는다.
dist/·build/·generated/같은 산출물 디렉터리의 패턴은 절대 문서화하지 않는다.devDependencies는 프로덕션 스택이 아니다. 린터·테스트 도구는 개발 도구로 분리해 기록한다.테스트 디렉터리의 TODO는 커버리지 공백이지 프로덕션 기술 부채가 아니다.
CONCERNS.md에서 구분한다.
4단계 워크플로
스킬은 체크리스트로 4단계를 강제합니다. Phase 1에서는 scan.py로 코드베이스를 스캔하고 PRD·README·SPEC 같은 의도 문서를 찾아 읽습니다. 흥미로운 점은 순서입니다. 소스 코드를 읽기 전에 프로젝트가 '하려던 일'부터 요약하게 합니다. 마지막 단계에서 의도와 현실의 차이를 짚기 위한 준비 때문입니다.
Phase 2에서는 문서별 조사 질문 목록(inquiry-checkpoints.md)을 따라 스캔 결과와 소스를 조사합니다. "파일 10개 이상을 확인해 네이밍 컨벤션을 파악하라"거나 "요청 하나를 진입점부터 데이터 저장소까지 추적하라"처럼 조사 행위 자체가 이 문서에 지시되어 있습니다. Phase 3에선 템플릿을 복사해 7개 문서를 채우고, Phase 4에서는 문서 전체를 검증 루프에 돌립니다. 근거 없는 주장이 없는지 확인하고 통과할 때까지 수정과 재검증을 반복한 뒤, [ASK USER] 항목을 번호 목록으로 제시하고 의도 대비 현실의 괴리를 정리합니다.
아키텍처 전체에 대한 분석이나 문서가 필요 없다면 focus mode를 쓰면 됩니다. "architecture only"처럼 범위를 지정하면 해당 문서를 우선 완성하고 나머지는 [TODO]로 남깁니다.
scan.py가 수집하는 것
Phase 1의 scan.py는 700줄 남짓한 파이썬 스크립트입니다.3 이 파일은 표준 라이브러리만 사용하고 프로젝트 파일을 수정하지 않습니다. 실행 결과를 통해 남는 산출물은 스캔 결과를 담은 출력 파일 하나뿐입니다. scan.py에서 수집하는 정보는 다음과 같습니다.
디렉터리 트리(깊이 3,
node_modules·dist등 제외)25개 이상 언어의 매니페스트 파일 미리보기(
package.json부터Cargo.toml,pubspec.yaml까지)진입점 후보와 린트·포맷 설정 파일
.env.example류 템플릿에서 뽑은 필수 환경 변수프로덕션 코드의 TODO·FIXME·HACK(테스트 디렉터리 제외)
최근 커밋 20개와 최근 90일간 수정이 잦았던 파일 상위 20개
모노레포 신호, 언어별 코드 지표, CI/CD·컨테이너·보안 설정
scan.py 코드에서 눈여겨볼 부분은 수집량 상한입니다. 스크립트 맨 위(26번 라인)에 디렉터리 트리는 최대 200항목, TODO 주석은 최대 60개, 매니페스트 미리보기는 앞 80줄이라는 상수가 선언되어 있고 모든 수집이 이 상한에서 잘리게 설계되어 있는 것을 확인할 수 있습니다. 이 제한 덕분에 파일이 만 개인 프로젝트든 십만 개인 프로젝트든 스캔 결과물의 크기가 비슷하게 유지됩니다. 스캔 결과는 결국 에이전트의 컨텍스트 창으로 들어가는 자료라서 무제한으로 수집하면 분석이 정확해지는 게 아니라 컨텍스트만 넘칩니다. 규칙을 더할수록 오히려 준수 품질이 떨어진다는 지침 예산 글의 문제의식이 스캔 스크립트 설계에도 그대로 적용되어 있습니다.
git 기록을 근거로 쓰는 방식도 실용적입니다. 최근 90일간 가장 자주 수정된 파일은 숨은 복잡도가 높고 변경이 위험한 영역일 가능성이 큽니다. 스킬은 이 고변경(high-churn) 파일 목록을 CONCERNS.md에 반드시 기록하게 합니다. 코드를 읽기도 전에 위험 지역 후보를 확보하는 셈입니다.
Copilot 밖에서 쓰기
저장소 이름은 Awesome Copilot이지만, 이 저장소에 있는 커스텀 에이전트·지침·스킬·훅·플러그인·에이전틱 워크플로는 이름과 달리 GitHub Copilot에서만 쓸 수 있는 것은 아닙니다. 스킬의 실체는 SKILL.md 지침과 파이썬 스크립트, 마크다운 템플릿 묶음이고 SKILL.md의 형식은 Claude Code의 스킬 규격과 같습니다. 그렇기 때문에 저장소에서 skills/acquire-codebase-knowledge 폴더를 ~/.claude/skills 아래에 복사하면 Claude Code에서도 그대로 동작합니다. 인수인계 직후 첫 세션에서 스킬을 호출해 7개 문서를 만들어 두면, 이후의 모든 작업 세션이 이 문서를 발판으로 삼을 수 있습니다.
정리
코드베이스를 인수인계받았을 때 필요한 것은 더 똑똑한 에이전트가 아니라 체계적인 절차입니다. acquire-codebase-knowledge 스킬은 조사 범위(7개 문서), 조사 방법(스캔과 질문 목록), 품질 기준(증거 기반 계약)을 모두 고정해 '분석해 줘'라는 요청을 재현 가능한 작업으로 바꿉니다.
직접 스킬을 만들 계획이 있다면 이 스킬 자체가 좋은 교과서입니다. 완료 조건을 계약으로 명시하는 방식, 모르는 것을 표시하게 하는 장치, 컨텍스트 한계를 고려한 스캔 설계까지 스킬 하나에 담겨 있습니다. 저장소에서 scan.py를 직접 읽어보길 권합니다. 대규모 코드베이스를 어떻게 요약 가능한 크기로 줄이는지 보는 것도 묘미입니다.
GitHub, Awesome GitHub Copilot, GitHub Repository.
↩GitHub, acquire-codebase-knowledge SKILL.md, awesome-copilot Repository.
↩GitHub, scan.py, awesome-copilot Repository.
↩
이 글은 모던웹연구소 (www.modernweblabs.com)에서 처음 발행되었습니다. © 모던웹연구소. 무단 전재 및 재배포를 금합니다.
뉴스레터
엔터프라이즈 현장 전문가들이 검증한 노트, 격주 발행.
Claude Code, GitHub Copilot, AI 네이티브 엔지니어링 전략과 도입 사례를 격주로 정리해 보내드립니다.
모던웹연구소 · 컨설팅 안내
글을 읽었다면, 다음은 팀에 이식할 차례입니다.
이 글에서 다룬 방식을 우리 팀에 어떻게 적용할지, 짧은 대화부터 시작하면 됩니다.
함께할 수 있는 일
AI 네이티브 전략
운영 표준·측정·거버넌스 재설계
Claude Code · GitHub Copilot
2일 핸즈온 + AI 채점 기반 사내 인증
웹 플랫폼
Next.js 기반 풀스택 서비스 구축